
FINAL UPDATE 1st September 2020: Ancestry will no longer display DNA matches below 8 cM. This article discusses techniques to preserve low matches before this change. These techniques are now obsolete.
Latest update 24 July 2020: Ancestry personnel have informed several users that
- the removal of matches will be delayed to
early Septemberlate August - starred matches will not be removed
- cM decimal places will be shown so you can tell which are below 8 cM
My only sources for this are from Facebook groups. Ancestry has not made an official announcement yet, but the sources are credible. I’ve added a section at the end of the article with the full details.
Latest update 31 July 2020: The bad news: the most recent date that Ancestry personnel have stated they’ll remove matches is now late August (not early September).
The good news: a Facebook user has shared a method to automate adding your desired matches to a custom group. It worked for me! I’ve added this section to give more details.
Latest update 20 Aug 2020: an alternative automation script was provided by another Facebook user. I’ve added the details and a link to a walkthrough video in this section.
Ancestry announced in mid July 2020 that they will remove DNA matches below 8 cM from your DNA match list. This will take place in early August. Up to now, their threshold has been 6 cM. Going forward, you will not see new matches appear below 8 cM.
So, what happens to the thousands of matches below 8 cM that you can see right now? They disappear from your match list, and you will not be able to see them again. But there are some exceptions, which means you have a short window to do something about your existing list.
How many DNA matches will YOU lose?
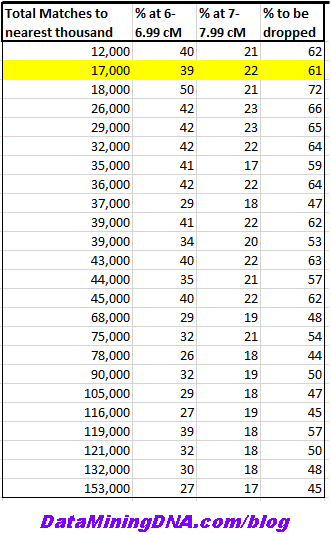
Before I get into actions, I want to put some numbers to this event. Although you can use Ancestry filters to display matches within a range of cM, you don’t get to see the counts. So you can’t estimate the percentage of matches you’ll lose using Ancestry’s website alone. However, I’ve assisted some Ancestry users to get a precise breakdown of their matches by cM thresholds. It’s not something I do any more (because Ancestry didn’t like it), but I’ve taken a look at the average percentages. This is based on 24 kits, with none managed by the same individual. The numbers are stark.
- The average percentage that 6-6.99 cM represents is 36% of total matches.
- The average percentage that 7-7.99 cM represents is 20% of total matches.
- The average loss of total matches will be 56%.
Of course, there’s variation within those averages. The lowest loss is 44% and the highest is 72%. Unfortunately, the highest percentages are those of use with the lowest number of total matches.
Personally, I have nearly 17 thousand matches (lower than most) and I’m looking at a loss of 61%.
You want raw numbers? Okay. For privacy, I’ve rounded the totals in the first column to the nearest thousand. The percentages were calculated off raw counts. The yellow highlight is my own kit, with my figures captured in May 2020. All other breakdowns were also calculated this year. I do have more numbers than these, but I wanted to use recent figures.
The exceptions that will be retained
Ancestry’s announcement lists certain types of matches that will be retained as exceptions. I summarize as:
- Matches to whom you’ve added a note
- Matches you have messaged
- Matches that you have added to a custom group
Note that starred matches are not included in this list i.e. they are for the chop. [Update 21 July 2020: Michelle Patient commented on this post that Ancestry has said that starred matches will be retained. I can’t find any clarification from Ancestry online, but Michelle is a trusted genealogist, so I’m happy to add the information to this post. Having said that, I will continue to play it safe and use a custom group.]
How to retain your low DNA matches
So, what do you do to avoid losing your matches? Well, maybe you do nothing. There are many Ancestry members who will welcome the reduction in low confidence matches.
Personally, I have a relatively small total number of DNA matches on Ancestry. Although I can’t do anything about future matches, I want to take steps to retain the ones I have – until I decide I can let them go. The other challenge is that at time of writing, I’ve got two weeks to take action. So whatever I do must be efficient. And I don’t want to re-invent the wheel, so I’ve taken a look around the interweb to what other people are doing. Roberta Estes in particular has a lengthy helpful piece.
Strategies from Roberta Estes
Roberta Estes offered a number of strategies on her blog to preserve matches. Her aim was to identify those low matches that are most likely to be useful to your research and add them to a custom group. If you already use groups, just go ahead and make a new one for this reclaim exercise. You can fine-tune them later.
Roberta has produced this in-depth article very quickly in response to a sudden announcement, and its really useful. But I do have some caveats or critiques that you can bear in mind.
I agree with using the Common Ancestors method to generate a list of DNA matches ordered by centimorgan, with whom Ancestry thinks you share an ancestor. That gives an efficient way of clicking any low matches. Roberta gives a step-by-step guide with pics, so I won’t repeat it here.
I’m not sure why a separate strategy is to use ThruLines. Doesn’t Common Ancestors give you the same info but with less clicks?
I don’t think the described strategy to use shared matches will work. Unless I’m reading it incorrectly. Ancestry doesn’t show us shared matches below 20 cM, so we’re not going to see these low matches on the shared match tab of a DNA match profile.
But I do like the strategy of searching for surnames or unique locations. There was a time when these search filters just did not function correctly, and could not be trusted. I vaguely remember that they also wouldn’t show matches below 20 cM at one point. But that’s not the case now. What I’ll offer here is advice to do some advanced preparation so that you’re not going scatter-gun. Draw up a list of surnames and places to target.
I skipped over the first strategy as so few people use third-party auto-cluster tools. If you do, go check out what Roberta has to say.
Watch me walk through some strategies
Check out the companion video on our YouTube channel. I walk through the strategies to retain your matches, and give my thoughts as I go.

Latest Update: the removal may be delayed until late August
The match removal has caused outcry amongst Ancestry members, who have contacted the company in several ways to protest at the changes and the lack of time for us to take action.
Furthermore, a growing number of African-American members have pointed out that they will be particularly adversely impacted by losing low matches. Clinton Moore has commented on this article about this serious matter.
Several people have reported in Facebook groups (from about 23rd July) that Ancestry staff have stated in a feedback meeting that the removal will be delayed by a month to early September. The latest news is that the cull will happen in late August. As of now, it’s still going ahead but we are getting more time to take the remedial action to keep the matches we want.
Ancestry have not made a formal announcement yet, so could this just be a false rumour? One of the Facebook users who have reported this is also an administrator of one of the largest Facebook Ancestry groups, so I’m inclined to believe it.
Another FB user wanted to be completely sure , so she contacted Ancestry support. She relates that three support desk personnel (junior) were not aware of this change in policy. Then she was passed on to a supervisor, who confirmed the delay but said there would not be a public announcement. That is so crazy in terms of customer relations that I believe it!
Are there better faster ways to retain matches?
The answer is, I’m not sure yet. If I figure something out, I’ll come back and document it. Well, I’m back to document a better faster way – I didn’t come up with it, but it’s worked for me.
An automated method to retain your matches
A chap on a private Facebook group has shared a method to automate adding DNA matches to a custom group. As it’s a private Facebook group, I’m not going to publish names in this blog. But here’s how to get all the details.
The Facebook group is called “AncestryDNA Matching”. If you submit a join request, you’ll probably get access within 24 hours.
The poster’s first name is Roger, and his post was published on 30th July 2020. As the post is popular – it may well be towards the top of the group. But you can search for this phase: “a small script in the Javascript language to apply automatic group tagging”
He had a prior version of the Javascript that he modified, so make sure you get the post of 30th July 2020. If you have never ran Javascript in your browser, there is a comment on the post that links to a YouTube video walkthrough that follows the steps.
It worked beautifully for me and for most other people commenting on the post. A few have had difficulties, and you’ll see trouble-shooting advice that may help you if you also have trouble. Basically, if you open his script in notepad and follow the video – you shouldn’t have a problem.
Update 20th August: an alternative script has been provided by Earl within the Facebook group “Ancestry Users”. Some people say it runs faster, and is easier to use with a large volume of matches. There’s a separate YouTube video walkthrough that follows the steps.
Looking for an e-book on building your Ancestry tree?

Check out our e-book on building your family tree with Ancestry.com. It’s available on Amazon now! Content includes:
- Setting up your DNA-linked tree
- Using your tree to find connections with DNA matches
- Best practices for entering names, dates, and locations
- Strategies for getting the most benefit from Hints
- Tips for using powerful Search features
If you would like to watch some short video tutorials that walk through using Ancestry features step-by-step, browse through the DataMiningDNA YouTube channel.
Thank you for the article and for putting some numbers on it – I like that kind of evaluation!
As a related note, I always thought that I had a low number of matches (compared to many of my friends, I do!) I have ~27,500 matches. It seems that I should expect ~65% of those to vanish with the changes (though I have worked this week to preserve more than 3000 matches listing births from counties where my ancestors are from. I continue to go through names…) I always wondered why I have fewer matches. Although most of my family lines have been in North America since 1700’s (some Dutch since 1630’s), I do have one set of great-grandparents that immigrated from Poland in 1906. Since not many Polish people seem to use Ancestry (more on myheritage!) I figured that is one possible reason. I also have several Irish ancestors that didn’t come until the great famine era ~1845-50. I was thinking that perhaps these more recent immigrants allowed for less generations in America for Ancestry DNA matches (which are mostly Americans) to develop. I also thought about large/small families – but I figured that evens-out after so many generations. I have a 5th great-grandparent that was the only child surviving to adult-hood, but she went on to have 11 kids, who in turn all had ~10 kids…. those situations seem to even out over time. So, I’m thinking it has more to do with the number of generations in America. Is that sound reasoning? Though I am still shocked when I hear of people having 70000-100,000+ matches! Given I have 1/4 of my family only here since 1906, and maybe another 1/4 since 1850, 1/2 of my family was here by 1740. Many of these Dutch and German families had tremendously big families, with more than a dozen kids reaching adulthood. By the generation reasoning along, it would seem that people with 60-100k matches must have had everyone here by 1650!?! The statistics for these matches intrigues me – why some have so many and others not as many. Any thoughts?
Chris, it’s a fascinating topic, I too am fascinated by the variation in volume of matches. I tend to take an analytic/stats view, same as yourself, and then we have the more complicating socio-economic factors. Who has the disposable income to take an Ancestry test? I’d expect people with the highest volume of matches to be middle class Americans whose ancestors’ descendants are middle class European. I’d love to see the whole breakdown of Ancestry customers’ breakdown and income – but that’s not gonna happen!
About the variation in volume of matches…
Between my husband, two kids, and me, I have multiple times more matches than the others. Some of my direct ancestors were poor, but all of them were Eastern European Jews. Endogamy explains the difference in volume of matches between my husband and I. That our (adopted) kids are from Russia explains their low volume. Thanks to Margaret and others here for sharing info; I’m sure I’m not the only appreciative one among those of us trying to learn.
Thank you for this analysis, Margaret. I’m not surprised that the average loss will be around 54%. I expect mine to be around 48-52% based on your chart.
I will add your post to my little compendium about the Ancestry purge.
Many thanks for your post – just one small correction – starred matches are considered to be a group and are not “for the chop” – Ancestry announced this clarification a few days ago.
Thanks, I’ll go check that out.
Thank you for making the impact of the proposed Ancestry change known. My son is African American. He has 16,000 DNA matches and close to half of those are 8 cM or less. Losing those matches will be significant, but what will be worse, is that it will stop him from seeing any future small DNA matches that could be clues to finding slave holders or family members that were separated during enslavement.
It’s not right and it’s not fair. We paid for the DNA test and results, and we should be the ones to opt in or opt out of having access to small DNA matches of less than 8cM. Seems as though Ancestry could charge extra for the service if they need to due to cost of data storage. I don’t believe that Ancestry has taken the time to fully consider how this new policy will affect African Americans.
Clinton, thank you for your insight. I was about to give you a link to a recent article from Roberta Estes, but I think I see you commenting there. It inspired me to message Ancestry’s support to point out the awful impact on African Americans.
I agree 100%. And not only are we losing those matches, but we are losing their trees also! Let’s face it, the trees that go with those matches are what is so valuable!
The 7.5 to 7.9 matches are rounded and show as 8cm. Some say those matches will be removed and some say they will stay.
Yes, I show in the linked video an example of a match of mine where I know the real cM has been rounded up in the display. I’d be surprised if they stay.
Margaret,
Since you have done some analytical work on the numbers, I thought you’d be interested in the potential impacts to ‘Thrulines’ which come about due to Ancestry’s changes.
There is a DNA test attached to my tree, but I have yet to begin analyzing the various DNA matches. So it’s pretty much untouched since I’ve been concentrating on my other tests. As of today, this particular test has 146 DNA matches below the 8 cM level that are flagged as having a ‘Common Ancestor’. They have now been added to a Group in the hope they ‘survive’ the impending changes. It would be a significant loss! Thought I’d pass along what I’m seeing from this end. Mine might be a bit of a worse-case, but I’m sure others with larger trees will also be seeing similar impacts on Thrulines at the 5th-8th cousin level…
Thank you for the insight, Mark, it’s very interesting.
Margaret, while a person with 20 cMs will not show ICW with others below 20, a match with 6 cM can still produce linked ICW matches over 20.
Yes, you’re right. It’s the old “hidden” matches, that don’t show each other reciprocally. I’ll take another look at my article, in case I’ve been misleading. Thanks for the comment.
In my case, this might prove to be a benefit. With having just shy of 118,000 matches due to both sides of the family being early colonial Virginian with a large glut of early 17th century arrivals with clear endogamy scenarios involving tight kinship groups in many cases surviving 400 or so years (turns out my parents are distant cousins)…cutting down on the numbers would make research a lot less avalanche like.
Not that DNA matching necessary provides sound proof in scanning against family tree research when attempting to proof potential family line discovery but being able to trace out kinship groups and their various branching paths provides a better sense of the families involved.
Good article.
Thanks, it’s great to get different viewpoints. And I understand how it makes research more manageable for people with a big total of matches.”Avalanche-like” is a good description.
I would have preferred if Ancestry had made it an opt-in choice for their users as whether to remove/include.
How do we get the script to run this program to automate tagging our low cMs?
The instructions are in the section titled “An automated method to retain your matches”. You need to join Facebook temporarily, if you don’t already have an account. Basically:
(1) Join Facebook
(2) Search for a group called “AncestryDNA Matching”
(3) Submit a join request to the group (may take them a day to action)
(4) The section in the post has a phrase you can use to search the group for the specific post with the script.