This article looks under the hood of the Ancestry Search Engine to explain some of the more crazy-looking search results.
A basic understanding of the Search Engine will help you get the best outcomes from your searches.
Why Are My Search Results So Broad?
Let’s take an example where you enter a search for John Smith of Albuquerque, New Mexico, born 1899.
That is a quite specific query. But as you scroll down the results, you may wonder why the Ancestry Search Engine shows you:
- marriage records from Santa Fe? And census records from Essex, England?
- birth records from 1890? And from 1820?
- records for Joan, Ione and Anna Smith?
To understand what’s going on, let’s start with the big picture.
An Overview Of How The Ancestry Search Engine Works
This is my 101 take from a 2019 academic conference paper from Ancestry.
Here’s the four-step helicopter view of what the Ancestry Search Engine must do when you hit the “Search” button.
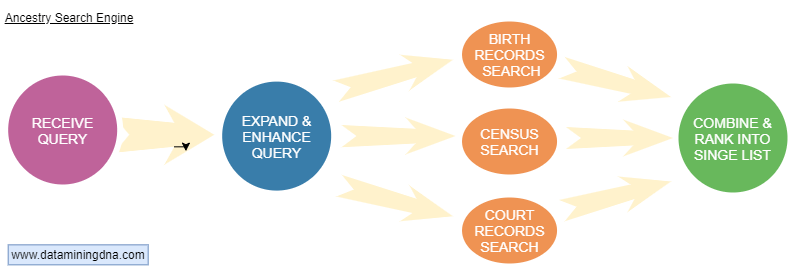
Let’s say you’ve entered a name, place and birth date into an Ancestry search form. The website sends your query to the Search Engine. That’s step one.
Now things get interesting…
Step Two: Expand & Enhance Query
Ancestry doesn’t just pass your search query unchanged to the processes that try to match with its records. The Search Engine sprinkles a little pixie dust to widen out what you’ve asked for. This pixie dust does things like:
- Adds common nicknames and abbreviations for a first name
- Adds common variants and misspellings for a last name
- Converts the date to a range before and after what you specified
- Tries to convert place names into standardized locations
Wait, you didn’t ask for the extras? Well, you get them unasked for, unless you tick the “Exact” checkboxes everywhere in your Search.
Ancestry isn’t doing this on a whim. Their research finds that our queries may be inaccurate, with typos and wrong spellings. Our dates are particularly prone to being off. This isn’t just Ancestry’s take on things. FindMyPast says similar about dates entered into its search forms. All the major genealogical search engines make allowances for inaccurate queries.
Right now you may be thinking that when you are absolutely sure of your facts, you’ll just make every search Exact. As you eye the thousands of results with different dates and names to what you entered, that pixie is looking more like the troll under the bridge.
But wait. Let’s look at the next piece of the Search Engine’s process.
Step Three: Specific Record Searches
Unless you’ve specified a particular collection, this step goes forth and multiplies your enhanced query into many slightly different enhanced queries. Each is sent off to work on a target collection.
Suppose you entered both birth and death dates and location.
One query throws away the death details and heads off to search for Birth records.
Another query ignores the birth dates, and tries to match names and locations with court records – which may not refer to the age of individuals mentioned.
And so on. I showed three collections in the graphic. In reality, there are many more queries sent simultaneously across Ancestry’s indexes. This is called a federated search.
Inaccurate Records
At this point, let’s think about what can go wrong from Ancestry’s point of view. Census ages are notoriously imprecise. The same court record taker may spell a name three different ways on a document. Women’s married and maiden names may be mixed up.
So now we have potential inaccuracies on both sides of the match: in the query and in the source. What’s your friendly neighbourhood Search Engine to do? If some of your details don’t match, but other details line up – the specific record search may widen out its arms to grab those kinda-maybe records too.
This is what can drive people nuts. Especially if you’re offered records from different countries, or for events that occurred before the birth of your ancestor.
When you’ve entered a name, place and location, sometimes it seems like Ancestry is saying with a shrug: “well, two out of three ain’t bad“.
How The Ancestry Search Engine Scores Records
To be fair, Ancestry doesn’t just shovel up swathes of records and throw them at you as if they’re all worth the same value. This step gives a score to each record. From “golden” down to “kinda-maybe”.
For example, suppose you searched for John Smith in Albuquerque, born 1899. Name matches get high points, lets say 100 (this is purely hypothetical).
If the record also mentions Albuquerque, more high points are added to the score. Let’s say 50 points for the city match. If the record mentions Santa Fe instead, it doesn’t get the 50 points, but it doesn’t get nothing added either. The Santa Fe record matches the broader state of New Mexico, so its given a generous 30 points.
The birth date is 1898, not 1899? That’s 49 points. These points are totted up for a total score for this record. Millions of other records within each collection are allocated their own scores.

Now these records and their scores are fed into the final step.
Step Four: Combine & Rank into a Single List
So lots of queries have run all over the place preparing lots of lists. But you see a single ordered list of results. How did that happen?
This final phase is the most technically complicated. A weighting is applied to each of the many lists. My educated guess is that birth records get a higher value than family trees.
Now each record has a collection weight and an individual record score. But the processing doesn’t end here.
More pixie dust is sprinkled in the form of machine learning to rescale and re-score records within each list. Say, what?
Basically, Ancestry is continuously testing the search process. Researchers enter search queries and evaluate what comes out the other end. Good and bad results are marked as such, and this is fed back to the automated process to adjust its scaling and scoring.
Finally, all the lists are mashed into one, with records shown in descending ranking order.
So, that search for John Smith of Albuquerque, New Mexico, born 1899? The higher scoring birth records will be ranked towards the top of the list. But when you start scrolling down to the lower scores, there’s Santa Fe. And John, Ione and Anna.
Other Articles On Ancestry Search
Now that you have a grounding in how the Ancestry Search Engine works, we can dive into using different aspects of searching on Ancestry.com. I advise that you move on to our article on Ancestry Global Search.
Here are some more articles that explore other types of search:
And this article is a round up twenty-four of our best tips and tricks:
Thanks for this, it is quite helpful. As a data scientist I appreciate what you are saying and how it is only scratching the complexity behind the searches.
A question about feedback. The website allows you to enter why you accepted, ignored, or maybe’d a hint. Does that info go back to Ancestry to assist their searches?
It’s a good question, but I don’t know if the user feedback is fed back into the search technology.
This year I have found many inaccurate spellings which are so illogical. Frankly I wondered if they were using foreign transcribers who had no idea of western names!
Also there are an annoying number of source documents for baptism or marriage which took place sometimes up to 200 years before the person of a similar name was born.
I have to give my email address when I report all these inaccuracies but I never get a reply that the detail has been corrected. That is also annoying and I sometimes wonder why I bother!!
Wow! This is the most well written and easy explanation I’ve ever read. Perfect for this “not a computer person”! Thank you.
Thank you – great to hear that it works for the non-tech person.